
一、前言
AQS 是抽象的队列同步器,是用来构建锁或其他同步组件的重量级基础框架及整个 JUC 体系的基石。
二、相关组件
下边的组件都是基于 AQS 框架扩展实现的:
- ReentrantLock:可重入锁,避免多线程竞争资源的安全问题
- Semaphore:信号量,限制多线程的访问数量
- CountDownLatch:计数器,用于线程之间的等待场景(如线程A等待其他多个线程完成任务后,线程A才能执行自己的任务)
- CyclicBarrier:回环栅栏,用于线程之间的等待场景(如在一组线程中,如果线程A执行到代码段S点就会停下等待,等到组内其他线程都执行到S点时它们才会立刻一起执行剩余的任务)
虽然这些组件在多线程场景下有不同的作用,但代码中也有相似之处,如都需要管理锁状态,维护阻塞线程,维护唤醒线程。而 AQS 的作用就是将这些相似的、公共的代码封装在一起。
三、运行原理
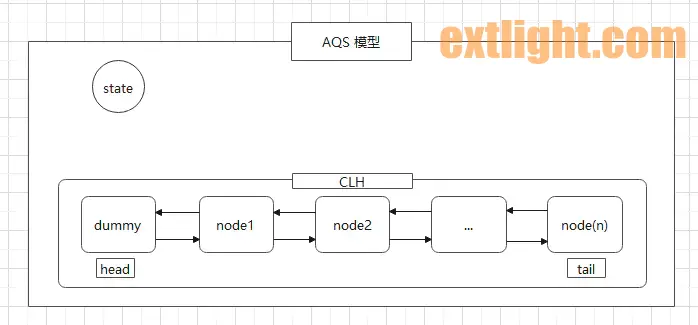
AQS 使用一个 volatile 的 int 类型的 state 变量来表示锁竞争状态,将每条要去抢占资源的线程封装成一个 Node 节点放入到内置的 CLH 同步队列(FIFO 双向队列)来维护排队工作,通过 CAS 对 state 值进行修改。
我们常说的 AQS 指的是 java.util.concurrent.locks.AbstractQueuedSynchronizer 类,其源码的核心如下:
1 | public abstract class AbstractQueuedSynchronizer extends AbstractOwnableSynchronizer implements java.io.Serializable { |
注意:源码中有个状态:一个是 state,针对资源抢占的状态;另一个是 waitStatus,针对 node 节点的状态。
将上文的源码转成图形,可便于我们理解,加深记忆,其运行模型图如下:
四、源码分析
文中涉及到 CAS 和 LockSupport 相关内容,不清楚的读者可以先跳至末尾,浏览相关的参考资料。
由于 AQS 并非单独使用,为了完整的讲解 AQS 的源码,本篇章以 ReentrantLock 组件为例,一步一步揭开 AQS 如何作为基石使用的。
- 演示案例
1 | public class LockTest { |
创建一把非公平锁,3 个线程通过抢占锁来执行任务。
此时,AQS 的模型如下:
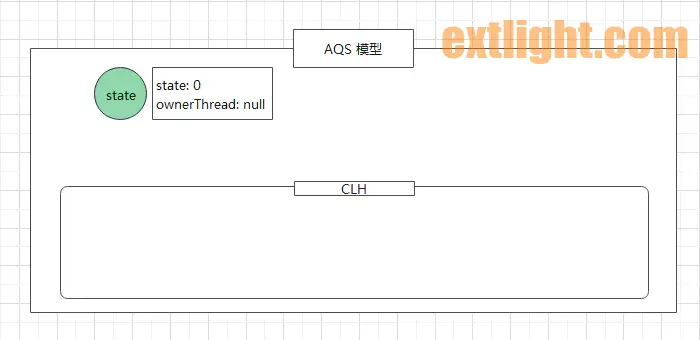
其中,state 表示锁的抢占状态,ownerThread 表示抢占锁的线程。
进入 lock() 方法,来到 ReentrantLock 源码中:
1 | public class ReentrantLock implements Lock, java.io.Serializable { |
可以看出 lock() 方法是通过 Sync 类来实现的。而 Sync 是一个抽象的静态内部类,它继承了 AbstractQueuedSynchronizer 类,因此它具备了 AQS 的“能力”。
Q1: Sync 定义了抽象的 lock() 方法,需要通过其子类来实现具体的锁方式(模板方法模式)。为何要这要设计的? 当然是为了方便扩展。
我们都知道通过 ReentrantLock 类能创建公平锁和非公平锁,其原因是 Sync 有两个实现类: FairSync 和 NonfairSync,它们都实现了 lock() 的具体细节。案例中,我们创建出的 lock 实例底层使用到的就是 NonfairSync 的实例(多态特性),即非公平锁。假设哪天 ReentrantLock 需要新增第三种锁,只需新增个子类继承 Sync ,实现 lock() 方法即可。
演示案例中我们创建的是非公平锁,我们来看看 Sync 对应非公平锁的子类 NonfairSync ,它同样是定义在 ReentrantLock 的静态内部类:
1 | public class ReentrantLock implements Lock, java.io.Serializable { |
我们开始沿着演示案例讲解:
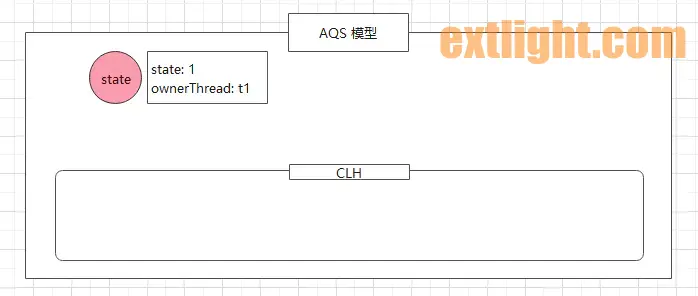
假设 t1 线程率先启动获取到 CPU 资源调用了 lock() 方法,执行到 (1) 处,即 compareAndSetState(0, 1),该方法来自 AQS。通过 CAS 方式将 AQS 中的 state 值变成 1,执行成功返回 true。
由于 t1 是第一条执行的线程,结果肯定返回 true,然后将 ownerThread 设置为当前线程 t1。最终整个 lock() 方法也成功返回,获取锁成功,执行自己的业务代码。
此时,AQS 的模型如下:
这时 t2 和 t3 线程也启动,“轮流” 执行到了 (1) 处,判断肯定失败,然后执行 (2),即 acquire(1) 方法,该方法来自 AQS。
我们进到 acquire(1) 方法中:
1 | public abstract class AbstractQueuedSynchronizer extends AbstractOwnableSynchronizer implements java.io.Serializable { |
假设当前线程为 t2,执行到 (4) 处,即 tryAcquire(arg) 方法,用于尝试获取锁。它是个抽象方法,由子类 NonfairSync 实现,NonfairSync 的 tryAcquire 方法最终调用其父类 Sync 的 nonfairTryAcquire() 方法来实现,可以返回至 (3) 处查看。
1 | abstract static class Sync extends AbstractQueuedSynchronizer { |
t2 线程进入到 nonfairTryAcquire() 方法,先获取当前线程(t2 线程),然后执行到 (8) 处,即 getState(),此方法来自 AQS,用于返回 AQS 的 state 状态。
由于 t1 线程没有释放锁,因此 state = 1、OwnerThread = t1 ,下边的 if 判断都不成立,最终方法返回 false。
回到 acquire() 方法中,由于返回 false,!tryAcquire(arg) 判断成立,t2 线程会继续执行到 (5) 处,即 addWaiter(Node.EXCLUSIVE),该方法用于将线程封装到 Node 节点中。
1 | public abstract class AbstractQueuedSynchronizer extends AbstractOwnableSynchronizer implements java.io.Serializable { |
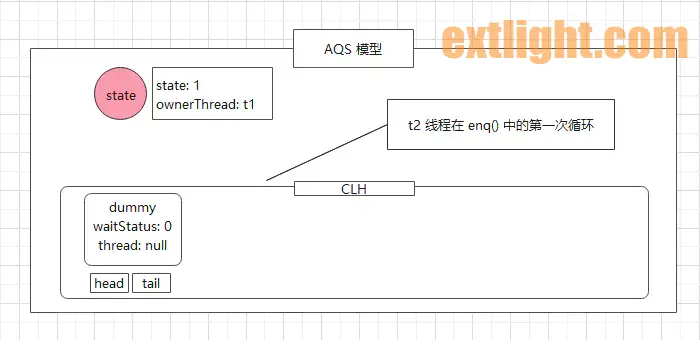
t2 线程进入到 addWaiter 方法中,先被封装到 node1 节点中,由于是首个线程被封装成 Node,因此 tail 和 pred 必定为 null,(9) 处的判断不成立,执行到 (11) 处,即 enq() 方法。该方法中开启无限循环,通过 CAS 方式设置 CLH 队列的头结点/尾节点。
第一次循环,由于 tail 为空,因此线程执行到 (12) 处,创建一个傀儡节点(无数据,用于占位)设置为头结点和尾节点。
此时,AQS 的模型图如下:
由于没有遇到循环终止的指令,将执行下一次循环。
在第二次循环中,尾节点不为空,因此进入(13) 处,将 node1 节点设置成尾节点,同时前后两个 node 节点建立关系,最终返回 node1 节点。
此时,AQS 的模型图如下:
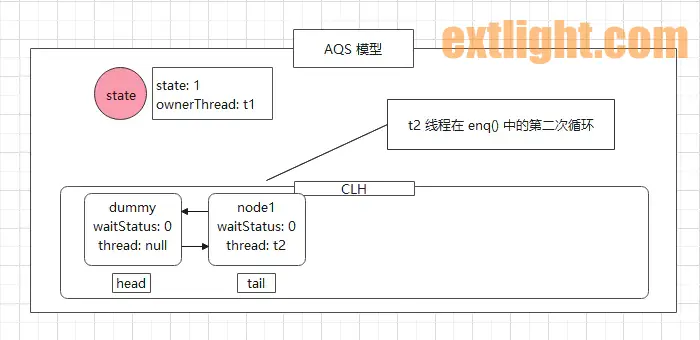
返回的 node1 节点后,t2 线程开始执行 (6) ,node1 节点被当作参数传入到 acquireQueued() 方法中,该方法用于将节点放入到 CLH 队列中,将其线程挂起等待。
1 | public abstract class AbstractQueuedSynchronizer extends AbstractOwnableSynchronizer implements java.io.Serializable { |
acquireQueued() 方法中也开启无限循环。在循环中,node1 节点先获取它的前驱节点(傀儡节点),然后判断是否为头结点,是则调用 tryAcquire()尝试获取锁,该方法在 (4) 处出现过一次,此处不再赘述。
由于 t1 线程还没有释放锁,(14) 处的最终判断肯定为 false。t2 执行到 (15) 处,即 shouldParkAfterFailedAcquire(),该方法用于修改 node1 节点的前驱节点的 waitStatus 状态。
Node 节点的 waitStatus 有以下 5 种状态:
| 状态 | 说明 |
|---|---|
| 0 | 初始状态 |
| 1 | 线程已取消 |
| -1 | 当前节点封装的线程释放锁后,会唤醒后继节点的线程 |
| -2 | 线程处在等待状态,在等待队列中 |
| -3 | 表示下一次的共享状态会被无条件的传播下去 |
1 | public abstract class AbstractQueuedSynchronizer extends AbstractOwnableSynchronizer implements java.io.Serializable { |
t2 线程进入 shouldParkAfterFailedAcquire() 方法中, 获取 node1 前驱节点的 waitStatus 状态,值为 0,直接跳到 (19) 处,通过 CAS 方式将 waitStatus 值改成 -1,最终的方法是返回 false 的。
此时,AQS 的模型图如下:
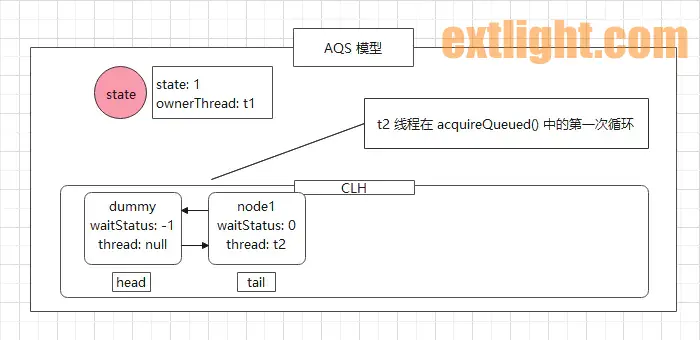
Q2: 为何在创建 node 节点封装线程时,不直接将 waitStatus 的值设置成 -1,而是专门定义这个方法进行修改? 答案我们留在下文解答。
shouldParkAfterFailedAcquire() 方法返回 false,t2 线程回到 acquireQueued() 方法中,由于之前是在无限循环中进行的,没有遇到终止指定,因此 t2 线程将执行第二次循环的操作。
毫无疑问,t2 线程又会再次执行 shouldParkAfterFailedAcquire() 方法,此时 node1 的前驱节点的 waitStatus = -1,最终方法返回 true。随后 t2 开始执行 (16),即 parkAndCheckInterrupt() 方法,用于线程等待。
1 | public abstract class AbstractQueuedSynchronizer extends AbstractOwnableSynchronizer implements java.io.Serializable { |
方法里边调用了 LockSupport.park(this),t2 线程立即被挂起,变成 WAIT 状态(此处的状态是线程的状态,与 AQS 中的 state 状态,Node 节点的 waitStatus 无关)。
假设 t1 线程仍未释放锁,轮到 t3 线程运行,不出意外其运行的最终结果也是被封装到 node2 节点,放到 CLH 队列中被挂起等待。
此时, AQS 的模型图如下:
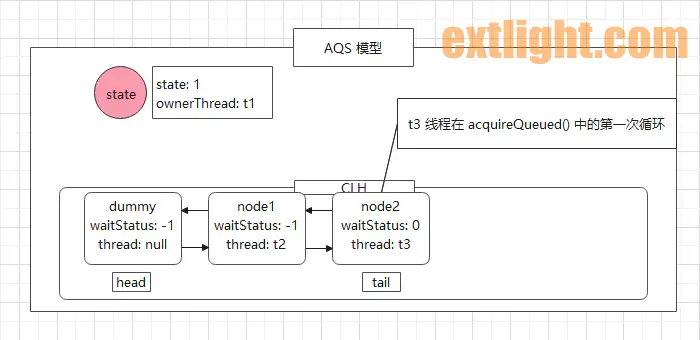
现在只有 t1 线程处在运行状态,当它运行完业务代码,随后执行 unlock() 方法:
1 | public class ReentrantLock implements Lock, java.io.Serializable { |
方法通过调用 Sync 的 release() 方法来实现,而 release() 方法来自 AQS:
1 | public abstract class AbstractQueuedSynchronizer extends AbstractOwnableSynchronizer implements java.io.Serializable { |
当 t1 线程执行到 (21) 处,即 tryRelease(arg) 方法,该方法都抽象方法,由 Sync 子类实现:
1 | public class ReentrantLock implements Lock, java.io.Serializable { |
进入该方法:
- 先获取 AQS 状态 state = 1,减去入参(值为 1),结果 c = 0。
- 判断当前线程(t1) 是否不等于 OwnerThread 的线程(t1),显然是相等的。
- 判断 c 是否为 0,判断成立设置返回值 free 为 true, 将 OwnerThread 线程设置为 null。
- 修改 AQS 状态为 c 的值,即 AQS 的 state = 0。
- 最终返回 free。
经过上述的操作,此时 AQS 模型图为:
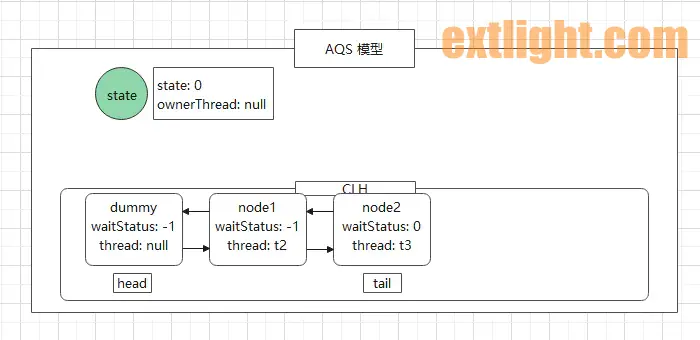
方法执行完回到 (21),条件判断成立,进入 if 方法体中:
- 获取头结点(值为 dummy 节点)
- 头节点进行非空判断 和 waitStatus 的非零判断(值为 -1),判断成立进入到 (23) 处,即
unparkSuccessor()方法,用于唤醒下个节点的线程。
1 | public abstract class AbstractQueuedSynchronizer extends AbstractOwnableSynchronizer implements java.io.Serializable { |
头结点被当作参数传入到 unparkSuccessor() 方法中,该方法执行 3 个操作:
- 将头结点的 waitStatus 状态恢复成 0。
- 获取头结点的后继节点,如果后继节点为空或 waitStatus 状态为已取消,则从后往前遍历 CLH 队列,获取非取消状态的节点。
- 唤醒后继节点中封装的线程。
回到案例中,线程执行到 (24) 处,获取的后继节点为 node1(封装 t2 线程)。来到 (25) 处,唤醒 node1 中的 t2 线程。
讲解到此处,大家是否还记得 Q2:为何在创建 Node 节点封装线程时,不直接将 waitStatus 的值设置成 -1。
我们以创建的 Node 节点时, waitStatus 值设置为 -1 为前提,进行案例推演:
- 依然是 3 个线程在运行,t1 线程先拿到锁执行业务代码。
- CPU 切换到 t2 线程,执行到 (5) 处,即
addWaiter(),被封装到 node1 节点中(waitStatus = -1),此时 node1 节点已经和头结点建立关系。 - 在 t2 线程执行 (16) 处,即在执行
parkAndCheckInterrupt()方法,t2 线程要被挂起之前,CPU 又切换至 t1 线程。 - t1 线程执行完业务代码,要释放锁时,会执行 (25) 处代码
LockSupport.unpark(s.thread);,唤醒 t2 。 - 但实际上 t2 线程并没有被挂起等待,如果某个线程被提前
unpark(thread),那么当该 thread 线程调用park()时是不会被挂起等待的,这样锁的机制就乱套了(线程未获取到锁,但又不挂起等待)。
因此,Node 节点的 waitStatus 值不能一开始被设置的成 -1。
回到正常案例中,t1 线程唤醒 t2 线程结束任务。t2 线程被唤醒并拿到 CPU 资源,执行到 (20) 处,即 Thread.interrupted() 方法,检测当前线程是否被中断,t2 线程并未中断,因此 parkAndCheckInterrupt() 方法返回 false。
1 | public abstract class AbstractQueuedSynchronizer extends AbstractOwnableSynchronizer implements java.io.Serializable { |
t2 线程将在 acquireQueued() 方法中进行第三次循环操作:
- 获取前驱节点 oldHead (dummy)
- 前驱节点是否为头结点,是则尝试获取锁。因为 AQS 的 state 已恢复成 0,因此 t2 可以成功获取到锁(修改 state = 1 和 ownerThread = t2)。
- 将 node1 节点设置为头结点(将前驱节点设置为 null,封装的线程设置为 null)
- 将 oldHead 节点的后继节点设置为 null。
此时,AQS 的模型图如下:
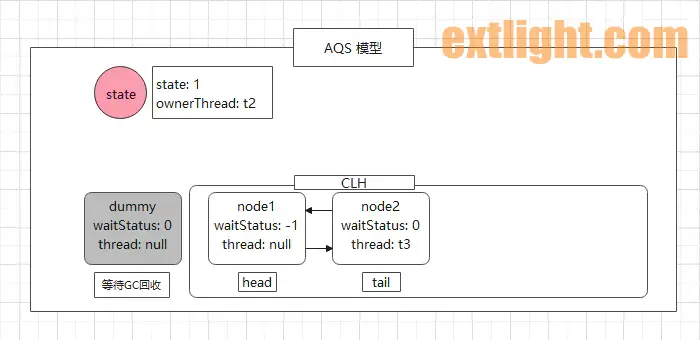
t2 线程获取到锁执行任务,之后释放锁。。。
t3 线程之后的执行流程与 t2 类似,此处也不在赘述。
五、执行流程
最后附加代码执行流程图:
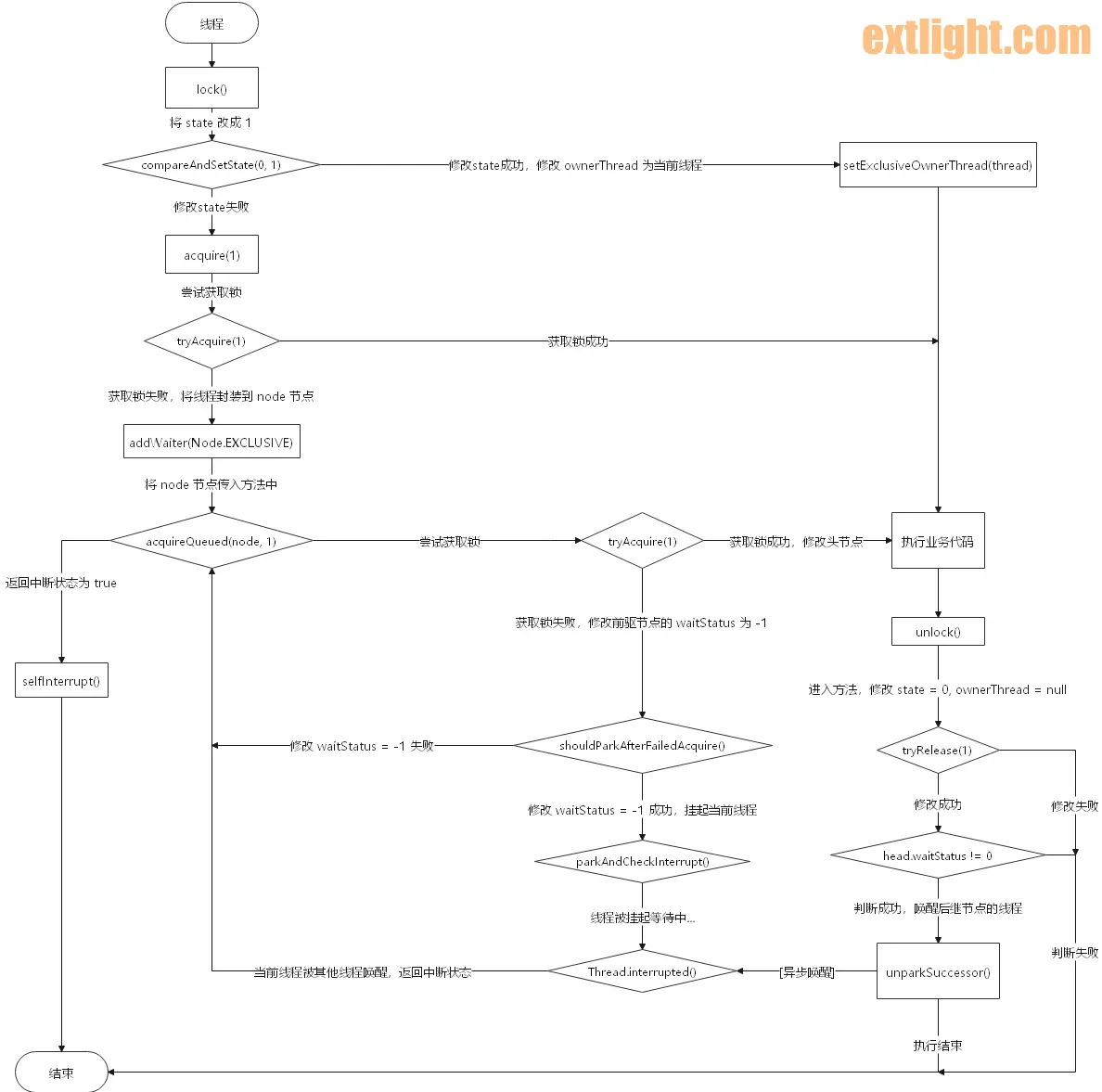
流程图并未充分展示执行的细节,最终还得需要读者自行阅读源码加深理解。


